시각화의 주요 특징
1. 비교/ 순위
- 실습) 1952년 아시아 대륙의 인구 분포에서 각 국가의 순위
gapminder %>%
filter(year==1952&continent=="Asia")%>%
ggplot(aes(reorder(country, pop), pop))+
geom_bar(stat="identity")+coord_flip()- reorder(x축 변수, 정렬기준변수)
- stat="identity": 막대그래프 그릴 때 넣어야하는 옵션
- coord_flip(): 가로축과 세로축의 위치 변경
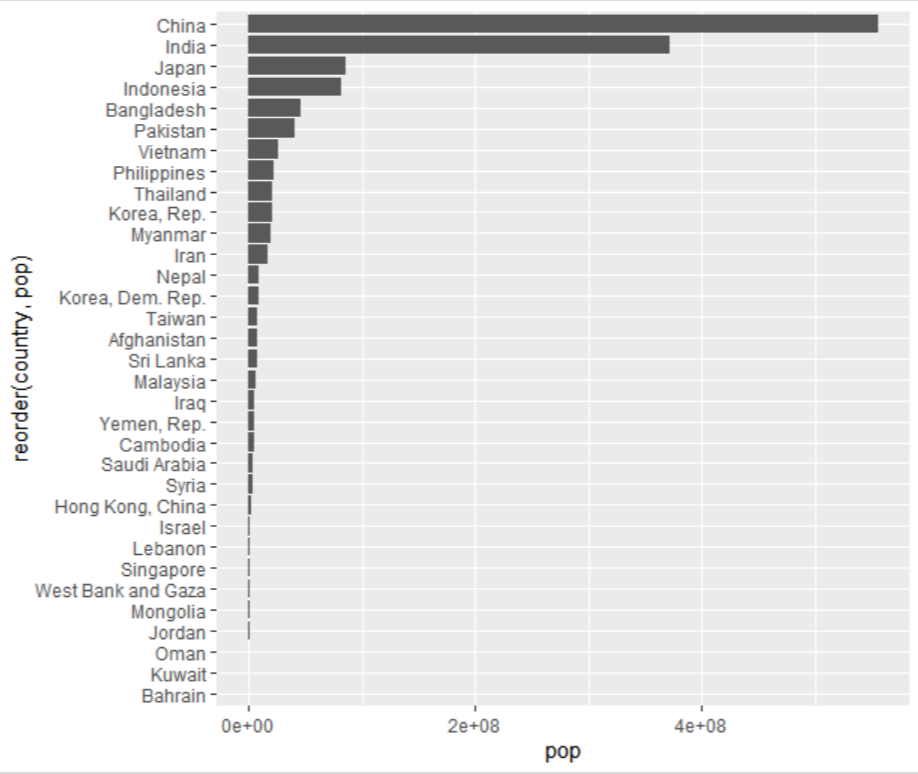
- 위의 그래프는 중국과 인도의 인구가 다른 국가에 비해 월등히 많아 싱가포르와 같은 인구가 적은 국가는 확인이 거의 불가.
- 이런 경우 로그 스케일의 축을 사용해서 큰 값은 작게, 작은 값은 상대적으로 크게 변환해야한다.
gapminder %>%
filter(year==1952 & continent=="Asia") %>%
ggplot(aes(reorder(country, pop), pop)) +
geom_bar(stat="identity") +
scale_y_log10() +
coord_flip()
- 데이터 간의 상대적인 차이를 직접 비교하거나 순위를 표시하는 데는 이런 막대그래프가 유리하다.
2. 변화 추세
- 실습) gapminder 데이터에 포함된 한국의 lifeExp 변화를 연도에 따라 시각화
gapminder %>%
filter(country=="Korea, Rep.") %>%
ggplot(aes(year, lifeExp, col=country))+
geom_point()+
geom_line()
- 여러 데이터의 변화를 동시에 비교할 때는 다음과 같이 색상으로 구분된 다중 플롯을 사용한다.
- 단, continent와 같은 범주형 속성을 이용해 구분이 가능해야 한다.
- 여기에 ggplot2의 geom_smooth 함수를 이용해 평균적인 추세선을 표시할 수도 있다.
gapminder %>%
ggplot(aes(x=year, y=lifeExp, col=continent))+
geom_point(alpha=0.2)+
geom_smooth()
3. 분포 혹은 구성 비율
- 실습) 1952년 전 세계 lifeExp의 분포를 시각화.
x=filter(gapminder, year==1952)
hist(x$lifeExp, main="Histogram of lifeExp in 1952")
- ggplot 함수를 이용한 결과
x %>%
ggplot(aes(lifeExp))+
geom_histogram()
- 실습) boxplot 함수를 이용하여 대륙별로 세분화된 분포 특성 살펴보기
x %>%
ggplot(aes(continent, lifeExp)) +
geom_boxplot()
4. 상관관계
- 상관관계는 데이터에 내재된 의미와 인과관계를 설명하는 단서가 될 뿐만 아니라,
모델링을 통해 미지의 결과를 예측하는 데도 활용된다.
plot(log10(gapminder$gdpPercap), gapminder$lifeExp)
728x90
'Programing > R' 카테고리의 다른 글
| [R] ggplot2 라이브러리를 이용한 데이터 시각화 (0) | 2021.10.22 |
|---|---|
| [R] 베이스 R을 이용한 데이터 시각화 (0) | 2021.10.22 |
| [R] 데이터 시각화의 기본 기능_많은 양의 데이터를 효과적으로 관찰 (0) | 2021.10.20 |
| [R] 데이터 시각화란? (0) | 2021.10.19 |
| [R] 데이터 구조 변경 (0) | 2021.10.18 |



댓글